Topic Modeling Explained: LDA to Bayesian Inference
Search engines need to process an enormous amount of information (the entire internet!). It is widely believed that search engines use topic modeling, which has the capacity to analyze large amounts of text data while identifying underlying themes and connections between webpages.
Topic modeling offers a way to compress this data while preserving the statistical relationships crucial for ranking relevant results. When a search query doesn't contain the exact term or synonym, topic modeling can still identify related documents that share the same underlying theme.
Search engines' use of topic modeling is a fascinating but uncertain area. That’s because the inner workings of major search engines like Google and Bing are closely guarded secrets. We rely on observations and correlations to understand how they function. While studies show some correlation between topic modeling and search rankings, it doesn't definitively prove search engines directly use this technology.
But we do know that, while he was Research Director at Google, Edward Y. Chang was on a team that worked on Latent Dirichlet Allocation (LDA) which utilizes a parallel computing architecture that allows Google to leverage the massive computing power at its disposal. Many others employed by the major search engines have done similar work.
One thing we know for certain is that as search engine algorithms improve their ability to make sense of the vast quantities of web pages they crawl and index, the savvy search engine marketer will need to stay at the leading edge of these emerging technologies in order to add value to their clients.
Large language models (LLMs) are also making waves, offering alternative approaches to understanding search intent and content optimization. If used together properly, topic modeling and LLMs present potentially game-changing opportunities.
This article provides explanations for the following questions:
- What is topic modeling?
- What is a probability distribution?
- What is a Bayesian inference model?
- What is data mining?
- What is machine learning?
- Do search engines need topic modeling?
- Do search engine algorithms use topic modeling?
- How can search engine marketers use topic modeling?
- How could LLMs complement topic modeling?
What is Topic Modeling?
Topic models provide an efficient way to analyze large volumes of text. While there are many different types of topic modeling, the most common and arguably the most useful for search engines is Latent Dirichlet Allocation, or LDA. Topic models based on LDA are a form of text data mining and statistical machine learning which consist of:
- Clustering words into “topics”.
- Clustering documents into “mixtures of topics”.
- More specifically: A Bayesian inference model that associates each document with a probability distribution over topics, where topics are probability distributions over words.
What is a Probability Distribution?
A probability distribution is an equation which links each possible outcome of a random variable with its probability of occurrence. For example, if we flip a coin twice, we have four possible outcomes: Heads and Heads, Heads and Tails, Tails and Heads, Tails and Tails.
Now, if we make heads = 1 and tails = 0, we could have a random variable, X, with three possible outcomes represented by x: 0, 1 and 2. So the P(X=x), or the probability distribution of X, is:
- x=0 -> 0.25
- x=1 -> 0.50
- x=2 -> 0.25
In topic modeling, a document's probability distribution over topics, i.e. the mixture of topics most likely being discussed in that document, might look like this:
document 1
- θ’1topic 1 = .33
- θ’1topic 2 = .33
- θ’1topic 3 = .33
A topic's probability distribution over words, i.e. the words most likely to be used in each topic, might look like this for the top 3 words in the topic:
topic 1
- φ'1bank = .39
- φ'1money = .32
- φ'1loan = .29
What is a Bayesian inference model?
Bayesian inference is a method by which we can calculate the probability of an event based on some commonsense assumptions and the outcomes of previous related events. It also allows us to use new observations to improve the model, by going through many iterations where a prior probability is updated with observational evidence to produce a new and improved posterior probability. In this way the more iterations we run, the more effective our model becomes.
In topic modeling as it relates to text documents, the goal is to infer the words related to a given topic and the topics being discussed in a given document, based on analysis of a set of documents we’ve already observed. We call this set of documents a “corpus”. We also want our topic models to improve as they continue observing new documents. In LDA it is Bayesian inference which makes these goals possible.
What is data mining?
Data mining is the search for hidden relationships in data sets. The data warehouse is typically a large, relatively unstructured collection of tables which contain large amounts of raw data. Mining this dataset can be very time consuming and complicated, so the data is then preprocessed to make it easier to apply data mining techniques. Standard preprocessing tasks involve throwing out incomplete, uninteresting or outlier data, a process called “cleaning”, and processing the remaining data in such a way as to reduce it to only the features deemed necessary to carry out the mining. Each remaining entry is called a “feature vector”.
In topic modeling, we are mining a large collection of text. Cleaning involves stripping the data down to just words and then removing “stop words”. This avoids generating many topics filled with words like “the”, “and”, “of”, “to” etc. Sometimes a corpus results in most of the topics containing some common words, in which case you might need to add some corpus specific stop words.
At this point we have a large collection of feature vectors which we can mine. We make the determination of what we are interested in finding and proceed accordingly.
There are typically four kinds of things we are interested in finding:
- Clusters of data which are related in some way that is not found in the features
- Classifications of features and the ability to classify new data
- Statistical methods and/or mathematical functions which model the data
- Hidden relationships between features
In topic modeling we are interested in finding clusters of data, specifically clusters of words we call topics, and clustering documents into “mixtures of topics”.
What is machine learning?
Machine learning is implementing some form of artificial “learning”, where “learning” is the ability to alter an existing model based on new information. Machine Learning refers to techniques which allow an algorithm to modify itself based on observing its performance such that its performance increases.
There are several machine learning algorithms, but most of them follow this general sequence of events:
- Execute
- Determine how well you did
- Adjust parameters to do better
- Repeat until good enough
There are two general categories of machine learning algorithms.
- Supervised learning involves some process which trains the algorithm.
- Unsupervised learning algorithms will accept feedback from the environment and train themselves.
Topic modeling is a form of unsupervised statistical machine learning. It is like document clustering, only instead of each document belonging to a single cluster or topic, a document can belong to many different clusters or topics. The “statistical” part refers to the fact that it employs a Bayesian inference model, which is the statistical mechanism for how the topic model is able to accept feedback from the environment (the corpus) and train itself in an unsupervised manner.
Do Search Engines Need Topic Modeling?
In short, if they wish to accurately model the relationships between documents, topics and keywords, the answer is yes! Secondly, but just as important, search engines need to enable efficient processing of an exceptionally large corpus (the entire internet!). To do so, they need to drill the corpus down to a smaller, more manageable set of details without losing the underlying statistical relationships essential to effectively retrieving the most relevant results for a given search.
In many cases, search engines could return useful results with more basic techniques, such as:
- Basic keyword matching - if the word is in the document, return it. However, there is zero compression of a corpus here.
- TF*IDF - looking at how frequently a term appears in a document (TF = term frequency) versus how frequently it appears in the corpus overall (IDF = inverse document frequency). Little compression of a corpus.
- Latent Semantic Indexing (LSI) - based on capturing linear combinations of TF*IDF features, LSI allows you to return a document for a keyword search even if that keyword isn't found in the document, but a synonym is. This method achieves significant compression of the corpus by capturing most of the variance in the corpus through a small subset of the TF*IDF features.
However, if we consider a document which is highly related to a search term, but contains neither that term nor a synonym, a search engine will not be able to return that document. Probabilistic Latent Semantic Indexing (PLSI) overcomes that with topic modeling.
A document which is highly related to a search term will share many topics with the search term whether the exact term or one of its synonyms appears or not. The main problem with PLSI is that it is not a proper method for assigning probability to a document outside a training set. In other words, to accurately assign probability to a new document, it would be required to retrain the topic model on the entire corpus.
Given the fact that search engines are constantly crawling the web looking for new documents, a way to make sense of a previously unseen document without retraining the entire model is needed. PLSI is also unsuitable for an exceptionally large corpus because the number of parameters grows in a linear fashion with the number of documents in the corpus.
This is where Latent Dirichlet Allocation (LDA) comes into play. LDA is a proper generative model for new documents. It defines topic mixture weights by using a hidden random variable parameter as opposed to a large set of individual parameters, so it scales well with a growing corpus. It is a better approximation of natural human language than the previously mentioned methods. It is a Bayesian inference model which allows the model to improve as it continues to view new documents, just as a search engine does in constantly crawling the web.
In short, if a search engine wants to be both effective and scalable with a constantly growing web where topics are in constant flux, it needs a form of topic modeling like LDA.
Do Search Engine Algorithms Use Topic Modeling?
 What evidence do we have that search engine algorithms use topic modeling, apart from the obvious usefulness of topic modeling? The algorithms of major search engines like Google and Bing are proprietary information and not available to the public, so any useful evidence we have is going to be based on observations of search results.
What evidence do we have that search engine algorithms use topic modeling, apart from the obvious usefulness of topic modeling? The algorithms of major search engines like Google and Bing are proprietary information and not available to the public, so any useful evidence we have is going to be based on observations of search results.
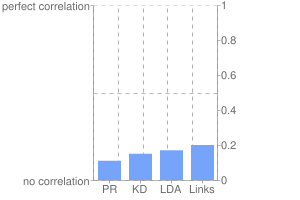
By observing millions of search engine results and analyzing them for dozens of potential ranking factors, we can determine correlations which provide a reasonable estimate of how search engine algorithms work. The graph to the right displays four significant correlations:
- PR = PageRank reported by Google Toolbar
- KD = Keywords in a domain
- LDA = Latent Dirichlet Allocation analysis
- Links = Number of followed links pointing from unique referring domains
It is widely accepted in the Search Engine Marketing community that links are the most important aspect of major search engine algorithms. LDA analysis involves calculating the similarity between a keyword and the content of the page the keyword resides on. This has a similar correlation to search engine rankings as links.
Most who are familiar with correlations will know that correlations between 0.15 and 0.20 by themselves aren't incredibly impressive. However, in the context of a search engine algorithm with over 200 ranking factors, it becomes a factor which cannot be ignored. Of course, correlation doesn't equal causation, but then again, the same could be said about links as a ranking factor.
How Can Search Engine Marketers (SEMS) Use Topic Modeling?
Even if you aren't convinced by the available evidence that search engines use topic modeling, there are still good reasons to use topic modeling analysis, many of which will be discussed below.
However, first SEMs must learn the topic modeling process.
- Select a topic modeling program. Options to consider include:
- lda-c - C implementation
- GibbsLDA++ - C++ implementation
- MALLET - Java implementation
- plda - C++ parallel implementation
- Start topic modeling program
- Import a corpus
- Train the model
- Selecting the number of topics - this must be set in advance and is usually set to between 200-400 but can often range from 50-1000. The larger the corpus, the more topics generally required. There are also algorithms which scan a corpus to determine an optimal number of topics prior to training the model.
- Selecting the number of iterations - this is essentially a balance between computer power/time and accuracy of the model. More iterations require more computing but make your model more accurate.
Once the model is trained, we can do things like:
- Output a list of all topics.
- Output a list of keywords for a topic, ordered by probability (i.e. the probability distribution table).
- Observe a new document and output the list of topics being discussed in that document.
- Compute similarities
- between words
- between topics
- between documents
- between words and documents
- between words and topics
- between documents and topics
While it is possible to analyze new documents without altering the existing model, chances are you will want your topic model to continue "learning" from the new documents you are having it analyze. In this way you will continue harnessing the power of machine learning; the more documents you analyze the more effective your topic model becomes.
Practical Search Engine Marketing Uses of Topic Modeling
- Selecting a keyword to optimize a given page.
- Determining the relevancy of the content on your page to the keyword you would like that page to rank for.
- Identifying content which could be added to a page that could improve your search engine rank for the desired keyword.
- Useful for creating keyword targeting strategies for sites with a large volume of pages.
- Useful in highly competitive searches where every leverage point available matters.
- Since topic modeling mirrors how humans process language, using topic modeling to guide keyword selection and content optimization strategies is likely to have beneficial second order effects like increasing backlinks and social shares.
- Finding topically relevant link acquisition targets.
- Identifying emerging trends in topics relevant to your website.
- Enhanced understanding of why pages rank where they do in the search engines.
How could Large Language Models complement topic modeling?
The emergence of generative AI platforms like Chat GPT and Gemini are potentially game changers for internet search evolution. These platforms use LLMs to analyze vast amounts of text data and learn the nuances of human language. LLMs can offer insights into searcher intent and how to optimize content accordingly.
All this implies, at least potentially, that LLMs could complement topic modeling. While topic modeling excels at uncovering the hidden relationships between words and topics, LLMs can analyze search queries and user behavior to understand the underlying intent behind a search. This suggests website content could be crafted that resonates not just with keywords, but also with the overall thematic landscape and the specific needs of the searcher.
By incorporating both topic modeling concepts and LLM insights, search engines may gain a significant edge in crafting content that resonates with search engines and users alike.
To Recap
Whether or not you utilize topic modeling in your search engine marketing campaign will depend largely on the level of sophistication of your search engine marketing team. The average SEO analyst is going to stick to things like link building, keyword research, and meta tag optimization; all techniques which are quite useful. However, if you want to take your campaign to the next level topic modeling, perhaps used together with a large language model, is something you should seriously consider.